昨天提到了集合的基本操作,及繼承樹,那我們再來更了解每個集合的特性吧
Set 是不允許重複元素的集合,不保證元素的順序,並且通常不是按照插入順序或排序順序存儲元素的。它主要關注的是元素的獨特性,確保一個元素不會出現多次。Set 集合是一個很好的選擇,當您需要確保一個集合中的元素都是唯一的,而順序並不重要時,就適合用Set。
方法:
可使用方法基本上和Collection 基本相同,沒有提供任何額外的方法,只是要注意不能包含重複元素
**HashSet:**最常使用的實作類別,HashSet按Hash 演算法來儲存集合中的元素,因此具有很好的存取和尋找功能
判斷兩個元素相等的標準是兩個物件通過equals()方法比較相等、並且兩個物件的hashCode()方法返回值也相等
**LinkedHashSet:**LinkedHashSet 同樣也是根據元素的hashCode值來決定元素儲存位置,但它保留了元素的插入順序,因此在迭代時可以按照插入順序訪問元素,因為需要維護元素的插入順序,因此效能略低於HashSet
**TreeSet:**是SortedSet介面的實作類別
有多提供額外的方法-https://docs.oracle.com/en/java/javase/11/docs/api/java.base/java/util/TreeSet.html
TreeSet採用紅黑樹的資料結構來儲存集合元素,支援兩種排序方法:自然排序和自訂排序
自然排序:
TreeSet會呼叫集合元素的compareTo(Object o)來比較元素之間的大小關係,然後將集合元素按遞增排序
自訂排序:
通過Comparator 介面幫助,可藉由int comparator(T o1, T o2)方法,比較o1和o2大小,
返回正整數表明o1>o2 ;
返回0 表明o1 = o2 ;
返回負整數表明 o1 < o2 ;
public class HashSetExample {
public static void main(String[] args) {
// 創建一個 HashSet
Set<String> set = new HashSet<>();
// 添加元素
set.add("apple");
set.add("banana");
set.add("cherry");
// HashSet 確保元素唯一性,因此重複的元素不會被添加
set.add("apple");
// 遍歷並打印元素
for (String fruit : set) {
System.out.println(fruit);
}
HashSet<PersonDemo> s3 = new HashSet<>();
PersonDemo p1 = new PersonDemo("A");
s3.add(p1);
s3.add(new PersonDemo("T"));
s3.add(new PersonDemo("W"));
s3.add(p1);
System.out.println(s3);
}
//--------------------------
class PersonDemo{
String name;
public PersonX(String name) {
super();
this.name = name;
}
@Override
public String toString() {
return name ;
}
@Override
public int hashCode() {
return 100;
}
@Override
public boolean equals(Object obj) {
return true;
}
}
List 適用於有次序性、但元素可能重複的集合。List 集合在使用上和陣列有些類似, 因為 List 集合中的元素, 也都可透過索引 (index) 來存取。
因此 List 介面定義了一些與索引有關的方法, 除了繼承自 Collection介面的 add()、remove() 的新增移除元素方法, 也增加了可指定索引值來新增或移除元素的方法。
下面具個例子說明:
public class ListDemo01 {
public static void main(String[] args) {
ArrayList a01 = new ArrayList();
a01.add(100);
a01.add(78);
a01.add("小明");
a01.add(65);
a01.add(33.75);
//插入元素
a01.add(2, 90);
System.out.println(a01);
//取代舊元素
a01.set(2, 11);
System.out.println(a01)
for(int i=0; i<a01.size(); i++) {
String value = (String)list.get(i);//轉型錯誤
System.out.println("value:" + value);
}
}
}
ArrayList後面泛型如果未定義類型,是可以任意添加其他類型的值(是一個Object),放在記憶體後就會忘記他原本的型態,就不會檢查其類型,取出時預設為 Object 類型,此時強制轉型會拋出異常,ClassCastExecption(強轉型錯誤)
既然提到了我們就來更認識泛型吧!
instanceof 運算符號,同樣是因為類型擦除後所帶來的副作用,會導致無法判別public static <E> void yo1(E e) {
E elements = new E(); // Error
}
public static <E> void yo2(E e, Class<E> clz) {
E elements = clz.newInstance();
}
6.Java 中沒有所謂的泛型Array,同樣也是因為擦除,無法判斷是否是同一類型
<> 包住以下範例 (類型變數用 T 代表),T 為數據類型:
public class GenericClass1<T> {
private T data;
private GenericClass1() {
}
public GenericClass1(T data) {
this(); // 呼叫無參構造函數
this.data = data;
}
public T GetData() {
return data;
}
}
// 兩個泛型變量 T K...
public class GenericClass2<T, K> {
private T t;
private K k;
public GenericClass2() {
}
public void setDataT(T t, K k) {
this.t = t;
this.k = k;
}
public T getTData() {
return t;
}
public K getKData() {
return k;
}
}
有兩種拓展使用方式 extends and super 限制
? 不能設定也不能取值,目的是為了 類型檢查;作為引數,代表全部類型都可以接受<? extends X>,表示類型的 上限到 X 類,包含 X 類以及其衍生子類
<? super X>,表示類型的 下限是 X.class,包含 X 類 以及其父類(超類)
public static void test(ArrayList<? extends A> a) {
System.out.println(a);
}
//?=任何
//任何A或繼承A的子類可以通通放到ArrayList
public static void test2(ArrayList<? super A> a) {
System.out.println(a);
}
//任何A或A的父類、Object可以通通放到ArrayList
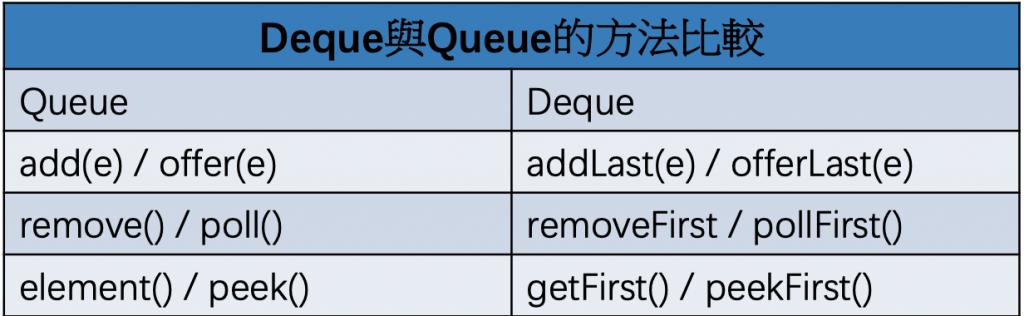
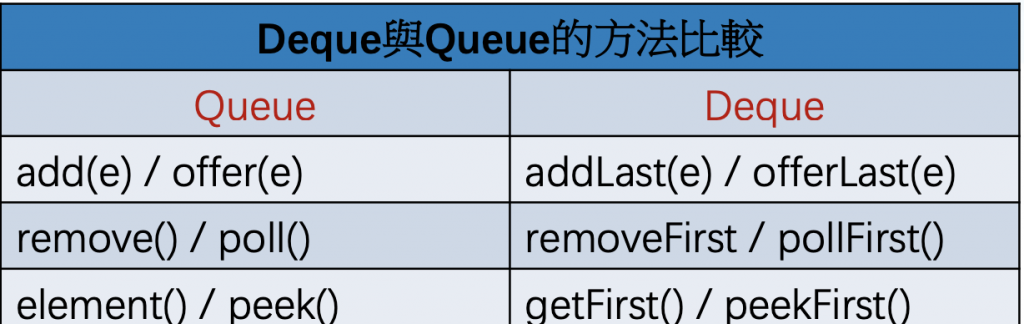
Queue 和 Deque 介面。這意味著它可以用作通用的 Queue 或雙端佇列(Double-Ended Queue)LinkedList 的特點是它提供了一組專門處理集合中第一個、最後一個元素的方法:void ensureCapacity(int minCapacity); //讓集合至少可以存minCapacity 個元素
void trimToSize() //釋放未用空間
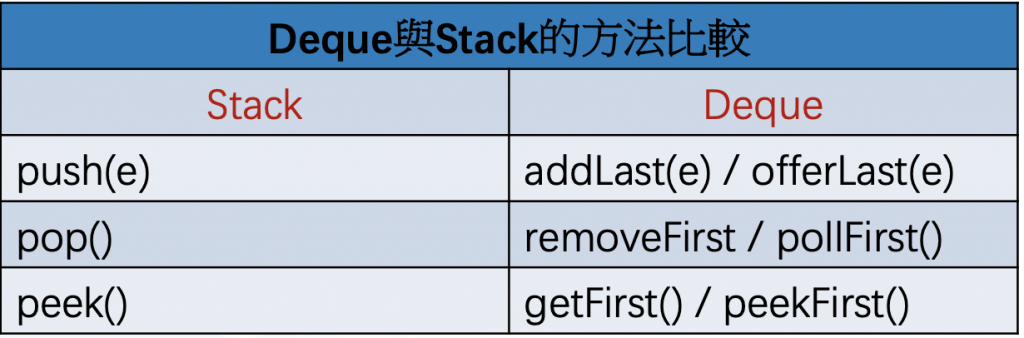
由於上述的特性, LinkedList 很適合用來實作兩種基本的『資料結構』(Data Structure):即堆疊及佇列。
所謂堆疊 (stack) 是指一種後進先出 (LIFO, Last In First Out) 的資料結構, 加入此結構 (集合) 的物件要被取出時, 必須等其它比它後加入的物件全部被拿出來後, 才能將它拿出來。
至於佇列 (queue) 則是一種『先進先出』 (FIFO) 的資料結構, 像日常生活中常見的排隊購物, 此隊伍就是個先進先出的佇列
遵循先進先出(FIFO)的原則,Queue 常用來處理需要按照特定順序處理的任務或資料。
明天最後一天拉~今天先到這邊!


 iThome鐵人賽
iThome鐵人賽